协同过滤
什么是协同过滤
“协同过滤”就是协同大家的反馈、意见一起对海量的信息进行过滤,从中山选出目标用户可能感兴趣的信息的推荐过程。
推荐过程
摘自书中。
(1)商品库一共有四件商品:游戏机、某小说、某杂志和某品牌电视机。
(2)用户X访问该电商网站,电商网站的推荐系统需决定是否推荐电视机给用户X。为了进行这项预测,可以利用的数据有用户X对其他商品的历史评价数据,以及其他用户对商品的历史评价数据。
(3)为了方便计算,将这些历史交互转化为矩阵的形式(称为共现矩阵),将用户作为矩阵的行坐标,商品作为列坐标,将用户交互行为数据作为矩阵中的数据(好评为1,差评为-1,没有交互为0或者有交互为1,没有为0)。
(4)生成共现矩阵后,推荐问题就转为成预测矩阵中没有交互的数据。协同过滤的核心就是考虑与自己兴趣相似的用户的意见。所以,第一步就是找到与用户X兴趣最为相似的n个用户,然后综合相似用户对“电视机”评价的预测。
(5)通过相似度和向量对最终结果进行排序,从而决定推荐系统是否向用户X推荐电视机。
此过程中关于“用户相似度计算”和“最终结果的排序”是不严谨的。下面进行这两步的形式化定义。
相似度计算
在协同过滤的过程中,用户相似度(或者物品相似度)的计算是算法中最关键的一步。共现矩阵中的行向量代表相应用户的用户向量,那么计算用户i和用户j的相似度问题也就是用户向量i和用户向量j之间的相似度,两个向量之间常用的相似度计算方法有以下几种。
余弦相似度
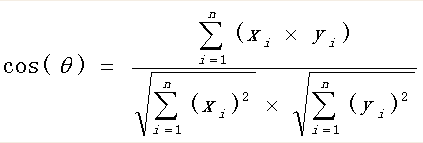
分子为两个向量的内积,分母为两个向量二范数的乘积。
皮尔逊相关系数
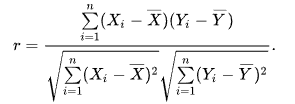
分子为两个向量的协方差,分母为标准差,Xi(Yi)表示用户对物品i的评价,减号后为用户对所有物品的平均值。
皮尔逊系数改进
将减号后的X改为所有用户评分的平均分。减少了物品评分偏置对结果的影响。
最终结果的排序
获得Top n相似用户之后,利用Top n用户生成最终推荐结果过程如下。这里最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测。
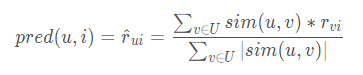
rui为用户u对物品i的评分,sim(u,v)表示用户u,v之间的相似度。
至此已完成协同过滤推荐的全过程。
基于用户相似度和基于物品相似度的过程大致相同,这里不多做赘述。
UserCF与ItemCF的应用场景
一方面,由于UserCF基于用户相似度进行推荐,使其具备更强的社交特性,用户能够快速得知与自己兴趣相似的人最近喜欢什么,也可能通过”朋友“的动态快速更新自己的推荐列表。这样的特点使其非常适用于新闻推荐场景。因为新闻本身的兴趣点往往是分散的,相比用户对不同新闻的兴趣偏好,新闻的及时性、热点性往往是其更重要的属性,而UserCF正适用于发现热点,以及跟踪热点的趋势。
另一方面,ItemCF更适用于兴趣变化较为稳定的应用,比如在Amazon的电商场景中,用户在一个时间段内更倾向于查找一类物品,这时利用物品相似度为其推荐相关物品是契合用户动机的。在Netflix的视频推荐场景中,用户观看电影、电视剧的兴趣点往往比较稳定,因此利用ItemCF推荐风格、类型相似的视频是更合理的选择。
协同过滤的下一步发展
协同过滤是一个非常直观、可解释性强的模型,但它不具备较强的泛化能力,换句话说,协同过滤无法将两个物品相似这一信息推广到其他物品相似性计算上。这就导致一个严重的问题,热门物品具有较强的头部效应,容易与大量物品产生相似性;而冷门的物品由于其特征向量稀疏,很少与其他物品产生相似性,导致很少被推荐。

