域因子分解机
FFM模型相对于FM模型,引入了特征域感知这一概念,使模型的表达能力更强。
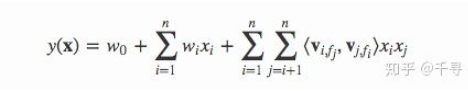
上图是FFM的数学表达形式。其与FM的主要区别在于每个特征对应的不是唯一一个隐向量,而是一组隐向量。当特征xi与xj进行交叉时,xi特征会从xi的这一组隐向量中挑出与特征xj的域fj对应的隐向量Vi fj进行交叉。
域
简单的说,这里的“域”代表特征域,域内的特征一般采用的是one-hot编码形成的一段one-hot特征向量。将所有的特征域连接起来,就组成了样本的整体特征向量。
举个栗子
在Criteo FFM的论文中有一个具体的例子,假设在训练推荐模型过程中接收到的训练样本如下图所示。
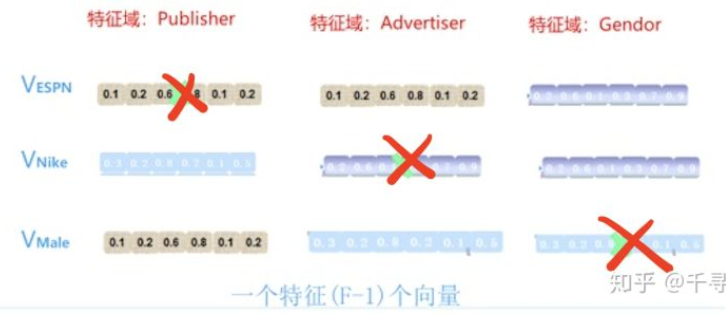
其中,Publisher、Advertise、Gender为三个特征域,ESPN、Nike、Male分别是这第三个特征域的特征值。
在FM中,特征ESPN、NIKE和Male都有对应的隐向量Wespn,Wnike,Wmale,那么ESPN特征与NIKE特征、ESPN特征与Male特征做交叉的权重应该是Wespn · Wnike和Wespn · Wmale。其中,ESPN对应的隐向量Wespn在两次特征交叉过程中是不变的。
而在FFM中,ESPN与NIKE、ESPN与Male交叉特殊的权重分别是Wespn,a · Wnike,p和Wespn,g · Wmale,p。这里使用的不同权值,这是由于ESPN、NIKE、Male分别在不同的特征域Publisher、Advertise、Gendor导致的。
优缺点
FFM模型的训练过程中,需要学习n个特征在f个域上的k维隐向量,参数数量共n·k·f个。
优点
相比于FM,FFM引入了特征域的概念,为模型引入了更多有价值的信息,使模型的表达能力更强。
缺点
在训练方面,FFM的二次项并不能像FM那样简化,因此其复杂度为k · n2。

