大规模分段线性模型
LS-PLM在2017年才被阿里巴巴公之于众,但其实早在2012年,它就是阿里巴巴主流的推荐模型,并在深度学习提出之前长时间应用于阿里巴巴的各类广告场景。
LS-PLM模型的主要结构
LS-PLM,又被称MLR(混合逻辑回归)模型。本质上,LS-PLM可以看作对逻辑回归的自然推广,它在逻辑回归的基础上采用分而治之的思路,先对样本进行分片,再在样本分片中应用逻辑回归进行预估。
在逻辑回归的基础上加入聚类的思想,其灵感来自R于广告推荐领域样本特点的观察。举例来说,如果CTR模型要预估的是女性受众点击女装广告的CTR,那么显然,我们不希望把男性用户点击数码类产品的样本数据也考虑进来,因为这样的样本不仅与女性购买女装的广告场景毫无相关性,甚至会在模型训练过程中扰乱相关特征的权重。为了让CTR模型对不同用户群体、不同使用场景更有针对性,其采用的方法是先对全量样本进行聚类,再对每个分类施以逻辑回归模型进行CTR预测。LS-PLM的实现思路就是由该灵感产生的。
LS-PLM的数学形式
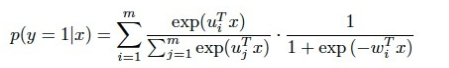
LS-PLM的数学形式如图所示,首先用聚类函数(这里用的softmax函数)对样本进行分类,再用逻辑回归模型计算样本分片中具体的CTR,然后将两者相乘求和。
其中的超参数“分片数”m可以较好地平衡模型的拟合与推广能力。当m=1时,LS-PLM就是普通的逻辑回归模型。m越大,模型的拟合能力越强。与此同时,模型参数规模也随m的增大而线性增长,模型收敛所需的训练样本也随之增长。在实践中,阿里巴巴给出的m的经验值为12。
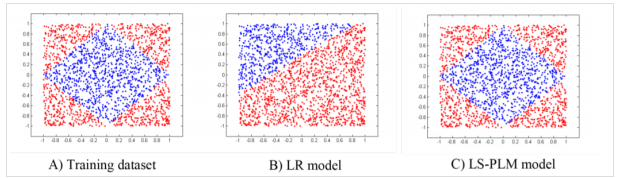
在上图中,分别用红色和蓝色表示两类训练数据,传统的逻辑回归模型的拟合能力不足,无法找到非线性的分类面,而MLR模型用四个分片完美的拟合了数据中的菱形分类面。
LS-PLM模型的优点
- 端到端的非线性学习能力:LS-PLM具有样本分片的能力,因此能够挖掘出数据中隐藏的非线性模式,省去了大量的人工样本处理和特征工程的过程,使LS-PLM算法可以端到端地完成训练,便于用一个全局模型对不同应用领域、业务场景进行统一建模。
- 模型的稀疏性强:LS-PLM在建模时引入了L1和L2,1范数,可以使最终训练出来的模型有较高的稀疏度,使模型的部署更加轻量级。模型服务过程仅需使用权重非零特征,因此稀疏模型也使其在线推断的效率更高。
为什么L1范数比L2范数更容易产生稀疏解
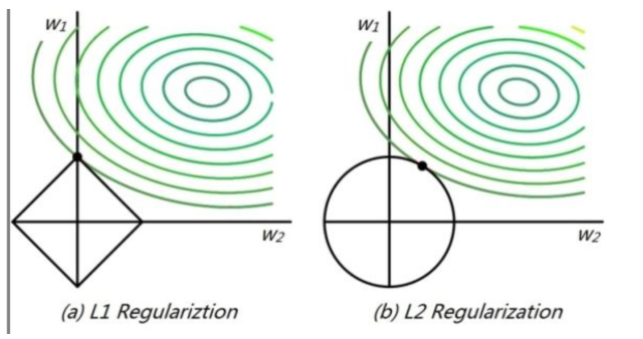
L2范数的曲线如图b的圆形,L1范数的曲线如图a的红色菱形。用绿色曲线表示不加正则化项的模型损失函数曲线。
求解加入正则化项的损失函数最小值,就是求解圆形和菱形上某一点和绿圈上某一点之和的最小值。这个值通常在范数代表曲线和绿色曲线的相切处(如果不在相切处,那么至少有两点值相同,与极值的定义矛盾),而L1范数曲线更容易与蓝色曲线在顶点处相交,这就导致除了相切处的维度不为零,其他维度的权重均为0,从而更容易产生模型的稀疏解。
从深度学习的角度重新审视LS-PLM模型
LS-PLM可以看作一个加入了注意力机制的三层神经网络模型,其中输入层是样本的特征向量,中间层是由m个神经元组成的隐藏层,其中m是分片的个数,对于一个CTR预估问题,LS-PLM的最后一层自然是单一神经元组成的输出层。
隐藏层和输出层之间,神经元的权重是由分片函数得出的注意力得分来确定的。也就是说,样本属于哪个分片的概率就是其注意力得分。
机器学习算法总结
| 模型名称 | 基本原理 | 特点 | 局限性 |
|---|---|---|---|
| 协同过滤 | 根据用户的行为历史生成用户-物品共线矩阵,利用用户相似性和物品相似性进行推荐 | 原理简单、直接,应用广泛 | 泛化能力差,处理稀疏矩阵的能力差,推荐结果的头部效应明显 |
| 矩阵分解 | 将协同过滤算法中的共现矩阵分解为用户矩阵和物品矩阵,利用用户隐向量和物品隐向量的内积进行排序并推荐 | 相较协同过滤,泛化能力有所增强,对稀疏矩阵的处理能力有所加强 | 除了用户历史行为数据,难以利用其他用户、物品特征及上下文特征 |
| 逻辑回归 | 将推荐问题转换成类似CTR预估的二分类问题,将用户、物品、上下文等不同特征转换成特征向量,输入逻辑回归模型得到CTR,再按照预估CTR进行排序并推荐 | 能够融合多种类型的不同特征 | 模型不具备特征组合的能力,表达能力较差 |
| FM | 在逻辑回归的基础上,在模型中加入二阶特征交叉部分,为每一维特征训练得到相应特征向量,通过隐向量间的内积运算得到交叉特征权重 | 相比逻辑回归,具备了二阶特征交叉能力,模型的表达能力增强 | 由于组合爆炸问题的限制,模型不易扩展到三阶特征交叉阶段 |
| FFM | 在FM模型的基础上,加入“特征域”的概念,使每个特征在不同域的特征交叉时采用不同的隐向量 | 相比FM,进一步加强了特征交叉能力 | 模型的训练开销达到了O(n2)的量级,训练开销较大 |
| GBDT+LR | 利用GBDT进行“自动化”的特征组合,将原始特征向量转换成离散型特征向量,并输入逻辑回归模型,进行最终的CTR预估 | 特征工程模型化,使模型具备了更高阶特征组合的能力 | GBDT无法进行完全并行的训练,更新所需的训练时长较长 |
| LS-PLM | 首先对样本进行分片,在每个分片内部构建逻辑回归模型,将每个样本的各分片概率与逻辑回归的得分进行加权平均,得到最终的预估值 | 模型结构类似三层神经网络,具备了较强的表达能力 | 模型结构相比于深度学习模型仍比较简单,有进一步提升的空间 |

