AutoRec
AutoRec将自编码器的思想和协同过滤结合,提出了一种单隐藏层神经网络推荐模型。
自编码器
顾名思义,自编码器是指能够完成数据“自编码”的模型。无论是图像、音频还是数据,都可以转换成向量的形式进行表达。其主要步骤是一个自编码器接受输入,将其转换为高效的内部表示(一般维度远小于输入),然后再输出输入数据的类似物。其目标便是使输入和输出的差距尽可能小。因此自编码器相当于完成了数据压缩和降维的工作。
经过自编码器生成的输出向量,由于经过了自编码器的“泛化”过程,不会完全等同于输入向量,也因此具备了一定的缺失维度的预测能力,这也是自编码器能够用于推荐系统的原因。
AutoRec模型的结构
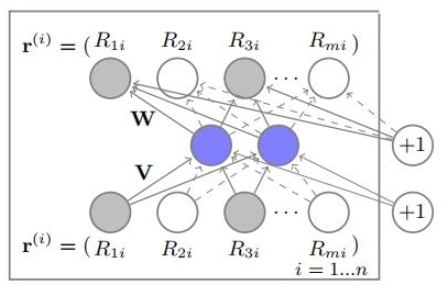
AutoRec的模型结构如上图所示,它使用单隐藏层神经网络的结构来解决构建自编码器的问题。假设网络的输入层是物品的评分向量r,图中V和W分别代表输入层到隐藏层,隐藏层到输出层的参数矩阵,输出层是一个多分类器。该模型的输出向量的计算公式如下图。
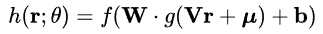
其中,f()和g()分别为输出层神经元和隐藏层神经元的激活函数。
为了防止重构函数的过拟合,加入L2正则化项后,AutoRec目标函数的具体形式如下图。
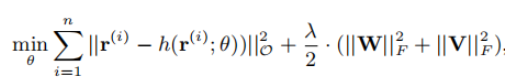
由于AutoRec模型是一个非常标准的三层神经网络,模型的训练利用反向传播即可完成。
基于AutoRec模型的推荐过程
基于AutoRec的推荐过程十分简单。当输入物品i的评分向量为r(i)时,模型的输出向量h(r(i);θ)就是所有用户对物品i的评分预测。通过遍历输入物品向量就可以得到用户u对所有物品的评分预测,进而根据评分预测排序得到推荐列表。
与协同过滤算法一样,AutoRec也分为基于用户和基于用品的。基于用户的AutoRec相比基于物品的AutoRec的优势在于仅需输入一次目标用户的用户向量,就可以重建对所有物品的评分向量。也就是说,得到用户的推荐列表仅需一次模型推断过程;其劣势是用户向量的稀疏性可能会影响模型效果。
AutoRec模型的特点和局限性
AutoRec模型使用一个单隐藏层的自编码器泛化用户或物品评分,是模型具有一定泛化和表达能力。由于AutoRec模型的结构比较简单,使其存在一定的表达能力不足的问题。

