Wide&Deep
模型的记忆能力与泛化能力
记忆能力:可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。一般来说,协同过滤、逻辑回归等简单的模型有较强的“记忆能力”。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产生类似于“如果点击过A,就推荐B”这类规则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。
泛化能力:可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。矩阵分解相比协同过滤的泛化能力强,因为矩阵分解引入了隐向量这样的结构,使得数据稀少的用户或者物品也能生成隐向量,从而获得有数据支撑的推荐得分,这就是非常典型的将全局数据传递到稀疏物品上,从而提高泛化能力的例子。再比如,深度神经网络通过特征的多次自动组合,可以深度发掘数据中的潜在模式,即使是非常稀疏的特征向量输入,也能得到较为平滑的推荐概率,这既是简单模型所缺乏的“泛化能力”。
简单模型的“记忆能力”强,深度神经网络的“泛化能力”强,那么设计Wide&Deep模型的直接动机就是将两者融合。
Wide&Deep模型结构
Wide&Deep具体的模型结构如下图。
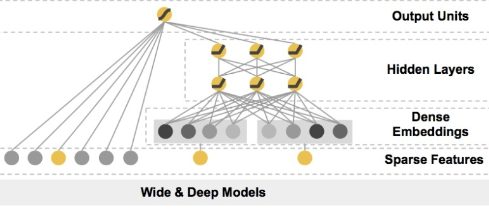
Wide&Deep模型把单输入层的Wide部分与由Embedding层和多隐藏层组成的Deep部分连接起来,一起输入最终的输出层。单层的Wide部分善于处理大量稀疏的id类特征;Deep部分利用神经网络表达能力强的特点,进行深层的特征交叉,挖掘藏在特征背后的数据模式。最终,利用逻辑回归模型,输出层将Wide部分和Deep部分组合起来,形成统一的模型。
在具体的特征工程和输入层设计中,展现了Google Play的推荐团队对业务场景的深刻理解。从下图中可以详细地了解到Wide&Deep模型到底将那些特征作为Deep部分的输入,将哪些特征作为Wide部分的输入。
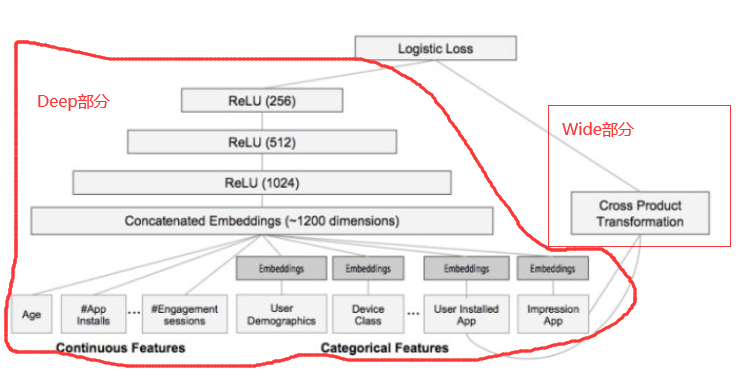
Deep部分的输入是全量的特征向量,包括用户年龄(Age)、已安装应用数量(#APP Install)、设备类型(Device Class)、已安装应用(User Installed App)、曝光应用(Impression App)等特征。已安装应用、曝光应用等类别型特征,需要经过Embedding层输入连接层(Concatenate Embedding),拼接成1200维的Embedding向量,再一次经过三层ReLU全连接层,最终输入Logistics Loss输出层。
Wide部分的输入仅仅是已安装应用和曝光应用两类特征,其中已安装应用代表用户的历史行为,而曝光应用代表当前的待推荐应用。选择这两类特征的原因是充分发挥Wide部分“记忆能力”强的优势。简单模型善于记忆用户行为特征中的信息,并根据此类信息直接影响推荐结果。
Wide部分组合“已安装应用”和“曝光应用”两个特征的函数被称为交叉积变换函数,其形式化定义如下图:
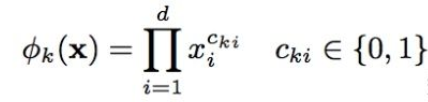
Cki是一个布尔型变量,当第i个特征属于第k个特征组合时,Cki的值为1,否则为0;xi是第i个特征的值。
在通过交叉变换层操作完成特征组合之后,Wide部分将组合特征输入最终的Logistic Loss输出层,与Deep部分的输出一同参与最后的目标拟合,完成Wide与Deep部分的融合。

