强化学习与推荐系统的结合
强化学习是近年来机器学习领域非常热门的研究话题,它的研究起源于机器人领域,针对智能体在不断变化的环境中决策和学习的过程进行建模。在智能体的学习过程中,会完成收集外部反馈,改变自身状态,再根据自身状态对下一步行动进行决策,在行动之后持续手机反馈的循环,简称“行动-反馈-状态更新”的循环。
“智能体”的概念非常容易让人联想到机器人,整个强化学习的过程可以放到机器学习人类动作的场景下理解。如果把推荐系统也当作一个智能体,把整个推荐系统学习更新的过程当作智能体“行动-反馈-状态更新”的循环,就能理解将强化学习的诸多理念应用于推荐系统领域并不是一件困难的事情。
2018年,由宾夕法尼亚州立大学和微软亚洲研究院的学者提出的推荐领域的强化学习模型DRN,就是一次将强化学习应用于推荐系统的尝试。
深度强化学习推荐系统框架
深度强化学习推荐系统框架是基于强化学习的经典过程提出的,读者可以借推荐系统的具体场景进一步熟悉强化学习中的智能体、环境、状态、行动、反馈等概念。如下图所示,框架图非常清晰地展示了深度强化学习推荐系统框架的各个组成部分,以及整个强化学习的迭代过程。具体地讲,其中各要素在推荐系统场景下的具体解释如下。
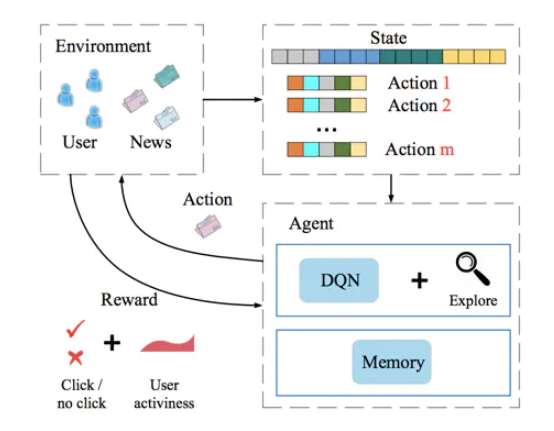
Agent: 智能体,推荐系统本身,它包括基于深度学习的推荐模型、探索(explore)策略,以及相关的数据存储(memory)。
Environment:环境,由新闻网站或App、用户组成的整个推荐系统外部环境。在环境中,用户接收推荐的结果并作出相应反馈。
Action:行动,对一个新闻推荐系统来说,“行动”指的就是推荐系统进行新闻排序后推给用户的动作。
Reward:反馈,用户收到推荐结果后,进行正向的或反向的反馈。例如,点击行为被认为是一个典型的正反馈,曝光未点击则是负反馈的信号。此外,用户的活跃程度,用户打开应用的间隔时间也被认为是有价值的反馈信息。
State:状态,指的是对环境及自身当前所处具体情况的刻画。在新闻推荐场景中,状态可以被看做已收到所有行动和反馈,以及用户和新闻的所有相关信息的特征向量表示。站在传统机器学习的角度,“状态”可以被看作已收到的、可用于训练的所有数据和集合。
在这样的强化学习框架下,模型的学习过程可以不断地迭代,迭代过程主要由如下几步:
- 初始化推荐系统(智能体)。
- 推荐系统基于当前已收集的数据(状态)进行新闻排序(行动),并推送到网站或App(环境)中。
- 用户收到推荐列表,点击或忽略(反馈)某推荐结果。
- 推荐系统收到反馈,更新当前状态或通过模型训练更新模型。
- 重复第二步
强化学习相比传统深度模型的优势就在于强化学习模型能够进行“在线学习”,不断利用新学到的知识更新自己,及时做出调整和反馈。这也是将强化学习应用于推荐系统的收益所在。
深度强化学习推荐模型
智能体部分是强化学习框架的核心,对推荐系统这一智能体来说,推荐模型是推荐系统的“大脑”。在DRN框架中,扮演“大脑”角色的是Deep Q-Network(DQN),其中Q是Quality的简称,指通过行动进行质量评估,得到行动的效用得分,以此进行行动决策。
DQN的网络结构如下图所示,在特征工程中套用强化学习状态向量和行动向量的概念,把用户特征和环境特征归为状态向量,因为他们与具体的行动无关;把用户-新闻交叉特征和新闻特征归为行动特征,因为其与推荐新闻这一行动相关。
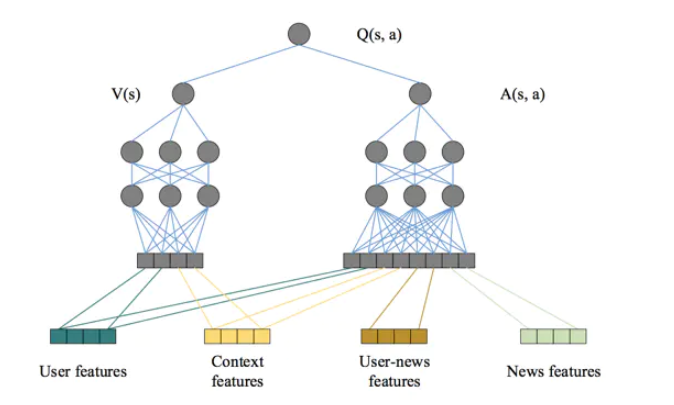
用户特征和环境特征经过左侧多层神经网络的拟合生成价值得分V(s),利用状态向量和行动向量生成优势(advantage)得分A(s,a),最后把两部分得分综合起来,得到最终的质量得分Q(s,a)。
事实上,任何深度学习模型都可以作为智能体的推荐模型,并没有特殊的建模方面的限制。
DRN的学习过程
DRN的学习过程是整个强化学习推荐系统框架的重点,正是由于可以在线更新,才使得强化学习模型相比其他“静态”深度学习模型有了更多实时性上的优势。下图已时间轴的形式形象地描绘了DRN的学习过程。
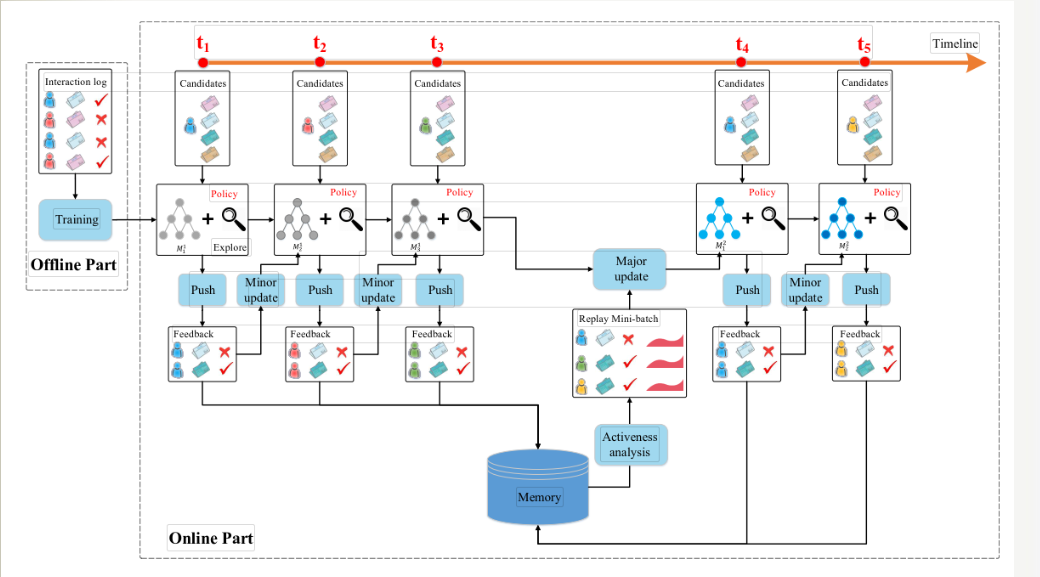
按照从左至右的时间顺序,依次描绘了DRN学习过程中的重要步骤。
- 在离线部分,根据历史数据训练好DQN模型,作为智能体的初始化模型。
- 在t1->t2阶段,利用初始化模型进行一段时间的推送(push)服务,积累反馈数据。
- 在t2时间点,利用t1->t2阶段累计的用户点击数据,进行模型微更新(minor update)。
- 在t4时间点,利用t1->t4阶段的用户点击数据及用户活跃度数据进行模型的主更新。
- 重复2-4步。
在第4步中出现的模型主更新操作可以理解为利用历史数据的重新训练,用训练好的模型替代现有模型替代现有模型。那么第3步中提到的模型微调怎么操作呢?这就牵扯到DRN使用的一种新的在线训练方法–竞争梯度下降算法。
竞争梯度下降算法
竞争梯度下降算法的流程如下图所示。
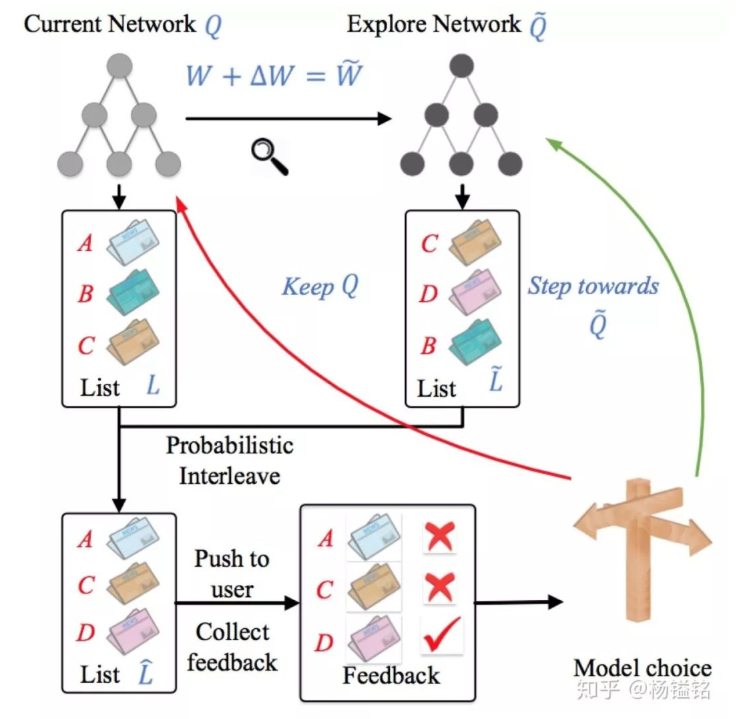
其主要步骤如下:
- 对于已经训练好的当前网络Q,对其模型参数W添加一个较小的随机扰动ΔW,得到新的模型参数
W,这里称W对应的网络为探索网络~Q。 - 对于当前网络Q和探索网络
Q,分别生成推荐列表L和L,用Interleaving将两个推荐列表组合成一个推荐列表后推送给用户。 - 实时收集用户反馈。如果探索网络~Q生成内容的效果好于当前网络Q,则用探索网络替代当前网络,进入下一轮迭代;反之则保留当前网络。
在第1步中,有当前网络Q生成探索网络~Q,产生随机扰动的公式如下图所示。
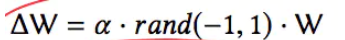
其中,α是探索因子,决定探索力度的大小。
DRN的在线学习过程利用“探索”的思想,其调整模型的粒度可以精细到每次获得反馈之后,这一点很像随机梯度下降的思路,虽然一次样本的结果可能产生随机扰动,但只要总的下降趋势是正确的,就能通过海量的尝试最终达到最优点。DRN正是通过这种方式,让模型时刻与最“新鲜”的数据保持同步,将最新的反馈信息实时地融入模型中。
强化学习对推荐系统的启发
强化学习在推荐系统中的应用可以说又一次扩展了推荐模型的建模思路。它与之前提到的其他深度学习模型的不同之处在于变静态为动态,把模型学习的实时性提到了一个空前重要的位置。
它也给我们提出了一个值得思考的问题–到底是应该打造一个重量级的、“完美”的,但训练延迟很大的模型;还是应该打造一个轻巧的、简单的,但能够实时训练的模型。

