AFM
AFM模型可以认为是NFM模型的延续。在NFM模型中,不同域的特征Embedding向量经过特征交叉池化层的交叉,将各交叉特征向量进行“加和”,输入最后由多层神经网络组成的输出层。问题的关键在于加和池化操作,它相当于“一视同仁”地对待所有交叉特征,不考虑不同特征对结果的影响程度,事实上消解了大量有价值的信息。
这里“注意力机制”就派上了用场,它基于假设“不同的交叉特征对于结果的影响程度不同,以更直观的业务场景为例,用户对不同交叉特征的关注程度应该是不同的”。举例来说,如果应用场景是预测一位男性用户是否购买一款键盘的可能性,那么“性别=男且购买历史包含鼠标”这一交叉特征,很可能比“性别=男且用户年龄=30”这一交叉特征更重要,模型投入了更多的“注意力”在前面的特征上。正因如此,将注意力机制与NFM模型结构和就显得理所应当了。
具体地说,AFM模型引入注意力机制是通过在特征交叉层和最终的输出层之间加入注意力网络实现的。AFM的模型结构如下图所示,注意力网络的作用是为每一个交叉特征提供权重,也就是注意力得分。
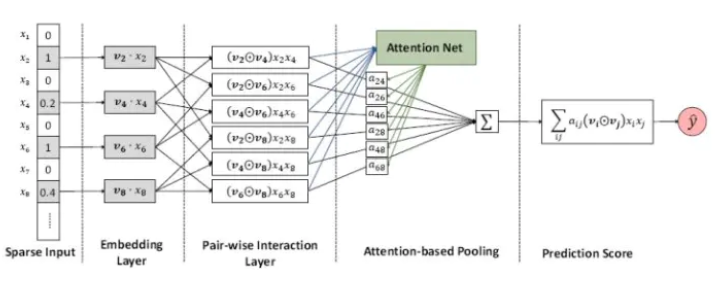
同NFM一样,AFM的特征交叉过程同样采用了元素积操作。AFM加入注意力得分后的预测公式为:
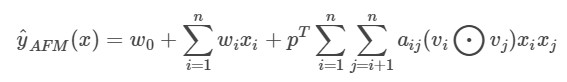
对注意力得分aij来说,最简单的方法就是用一个权重参数表示,但为了防止交叉特征数据稀疏问题带来的权重参数难以收敛,AFM模型使用了一个在两两特征交叉和池化层之间的注意力网络生成注意力得分。
该注意力网络的结构是一个简单的单全连接层加softmax输出层的结构,其数学形式如下图所示。
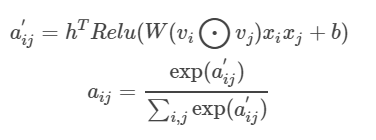
其中要学习的模型参数就是特征交叉到注意力网络全连接层的权重矩阵W,偏置向量b,以及全连接层到softmax输出层的权重向量h。注意力网络将与整个模型一起参与梯度反向传播的学习过程,得到最终的权重参数。
AFM是研究人员改进模型结构的角度出发进行的一次有益尝试。它与具体的应用场景无关。

